Leaf classification
Published:
Why Leaves?
From long time ago, people have already learned to identify different kinds of plants by examing their leaves. Nowadays, leaf Morphology, Taxonomy and Geometric Morphometrics are still actively investigated. Leaves are beautiful creations of nature, people today are frequently inspired by them for creations of art works. For example, Candian people use a maple leaf as the center of their flag. It would very nice if computers can help create leaves automatically from sratches. I assume this is a very difficult task. In order to make a beginner’s start, it may be beneficial to investigate what makes different leaves different from each other. This is a classification problem. Features learned from classification may help us have a peek at a glimpse of nature’s genius idea when it decides to make such creations. In industry, automatic recognition of plants is also useful for tasks such as species identification/reservation, automatic separate management in botany gardens or farms uses plants to produce medicines. It is also a good practice for me to learn things that are beyong textbooks.
Data sets
*UCI’s machine learning repository. A small data set. Algorithms may show large fluctuations with different train/test splits.
*Swedish leaf dataset. A benchmark data set that is used in many papers, this website lists some state-of-art methods to compare. (Maybe outdated.) The classifier is tuned based on this dataset.
*UCI’s 100 leaf. There was a Kaggle competition on this.
Some Previous Work
A lot of work has been documented. Generally speaking, efforts are focused on two directions:
- Features that have more discriminating power.
- Classifiers that can better discover hidden patterns from extracted features.
Main Feature
It may be good to start with some feature that is easy and generative and then check how much accuracy can be squeezed out of it. CCDC(Centroid Contour Distance Curve) seems to be a good choice. It is one of those shape features and relatively easy to extract. It also has some nice properties like translation, rotation (after certain alignment) and scaler invariant (after certain normalization). By applying a canny filter to colored images, the contour is then easily obtained. For point $(x, y)$ on the contour, we can then change it to polar coordinate $(r, \theta)$ by $r = \sqrt{(x-x_c)^2 + (y-y_c)^2}$ and $\theta = \arctan(\frac{y-y_c}{x-x_c})$ where $(x_c, y_c)$ is the center of image which can be computed by image moments. It is important that enough points are sampled so that CCD contains local details of the leaf. In the experiment done below, 200 points are sampled. Below are contours extracted from the original images.
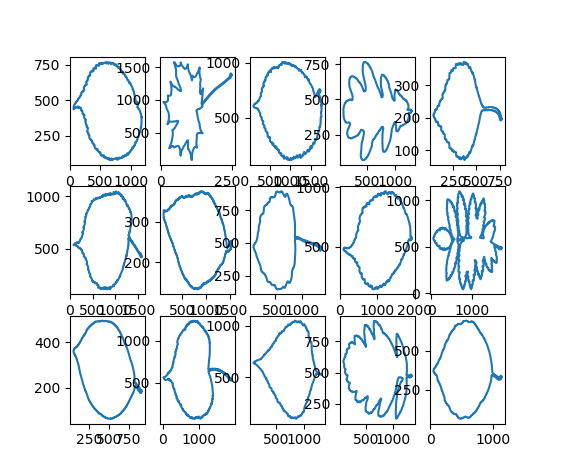
In this way, leaves are converted into time series and techniques for time serires can be applied. Some easy extension from this may include power spectra and auto correlation function (acf) can be extrated as signatures of the CCDC and be fed into the classifier. Fancier techinque like dynamic time warping (DTW) may also be applied. This website contains many algorithms for time series.
Main Classifier
As for the classifier, Convolutional Neural Networks now are popular and very effective in image classification tasks if trained properly. It combines feature extraction and classification together, which allows an end-to-end training. Due to the limited power of my laptop, I did not go too far with it. Since 1d feature is used, architectures for 1d data such as simple forward network with only layers are considered as the main classifier.
Exploration
The first attempt is to directly train a flat network with several dense layers with some regulations (Batchnormalization and dropout). The result is not very good, only 60%~70% accuracy. There is a big gap between training accuracy and validation accuracy in the learning curve. It may because the dataset is small so that the network is trained with bias. It may also because the simple architecture of the network is not powerful enough.
The data part
I searched for some suggestions of how to reduce the gap bewteen training/validation accuracy and improve the performance, this post provides a summary of some tips. I decided to expand the data by some augmentation. Working with CCDC, Two kinds of augmentation I took is fliping or shifting the 1d vector per sample in the training data.
The feature part
Putting different features in one bag may help bring up the performance. An neural net work is very easy to work with features extracted from different methods. You can just simly stack/concatenate those features at the input layer. I tried some combinations among features that can be obtained from CCDC such as power spectra, acf, distance histogram, curvature, approximation/detail coefficients from a discrete wavelet transform $\cdots$. The best performance is given by CCDC + power spectra + acf, which gives around 90% - 95% accuracy testing on the 30 classes UCI leaf data set.
The architecture part
Though maybe comparable, this result is still lower than some other methods tested on the Swedish leaf dataset. In order to squeeze more juice out of CCDC representation, the architecture of the simple network has to be changed. Some ideas of the architecture I thought will work well were:
- Adding shortcut connection between layers as did in the residual net to help training. Though my network is not deep at all, this does bring up a little performance.
- I noticed the fact that among those wrong predictions, the true class label usually ranked 2nd or 3rd in terms of probability. So I add a selection function that picks up top-2 classes when the highest probablity is less than a threshold (0.5 for example) for each test sample. For such a sample, I retrain a second stage classifier using svm or knn only with training samples from these picked two classes. I hope this could reduce the confusion for the classifier during training. The result of experiements turned me down… The boost for accuracy is not obvious.
- Since what the last layer does in the neural network is generally a linear classification. If I take this layer off, saving its input as further extracted features and train a classifier that has more power in nonlinear discrimination such as svm/knn on top of these features, it will perform better. It coincides with conents talked about in this post. This idea help bring up a few more percentages of accuracy. :)
I got stucked here for a while and one day the 1d convolution idea came to my mind when I was reading the moving average model. If we want to classify a time series, we need to study its signatures at different scales. A sliding window (kernel) for examination with different sizes and strides serves perfectly for such tasks. This idea help me form a new architecutre that looks the same as one naive module in Google’s Inception Net…
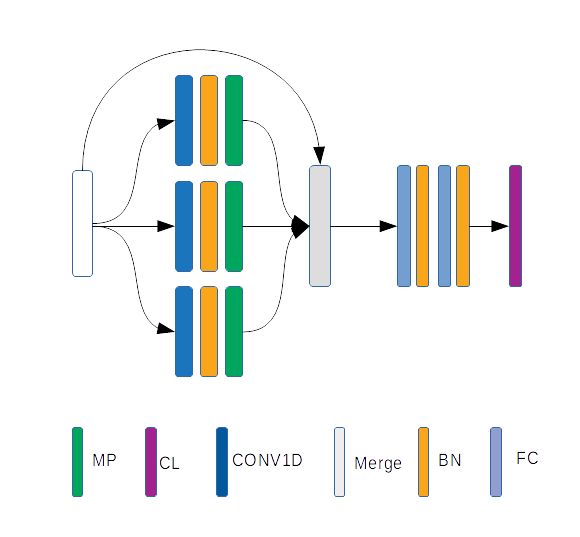
This architectures as a feature extractor for pretraining data and spits nearly linear separable features + pca + a kernel svm on top as a classifier turns out to perform pretty well. For all the three datasets mentioned (with 10% withholded as test set), it can reach to >90% accuracy without particular hyperparameter tuning. For the swedish leaf data set, particularly, it can get to >99% test accuracy. All these performance are achieved with only CCDC feature as input. This simply feature does contain much useful information and the idea of convolution is really impressive. If you would like to check out more details, please check the project repository.
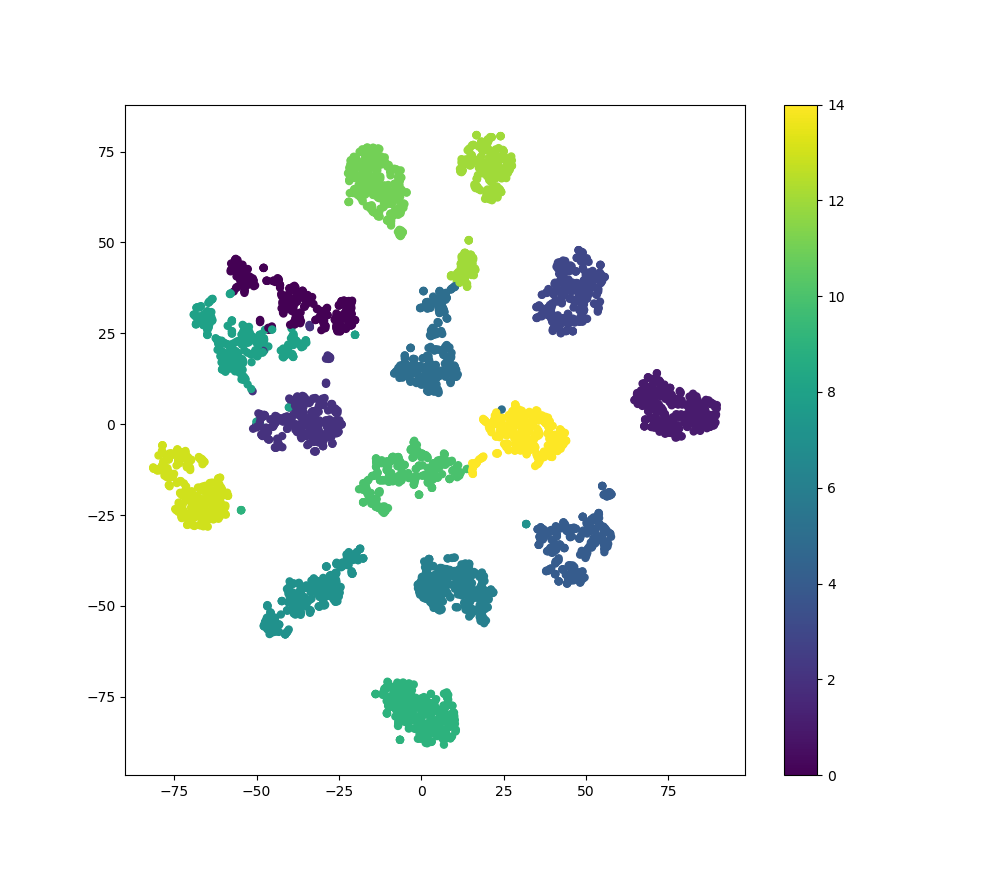
Here is a picture shown using TSNE algorithm that embeds features output from the network trained on swedish leaf dataset into the plane. As expected, 15 classes are almost linearly separable.
On classifying time series
This model actually works pretty good for classifying 1 dimensional time series. Its performance on some datasets on this website can be checked in the following table. The model is without any hyperparameter tunning.
| Dataset | Best Accuracy | Method | 1dCovNet |
|---|---|---|---|
| ChlorineConcentration | 90.41% | SVM(quadratic) | 99.77% |
| InsectWingbeatSound | 64.27% | Random Forrest | 76.61% |
| ElectricDevices | 89.54% | Shapelet Transform | 94.34% |
| DistalPhalanXTW | 69.32% | Random Forrest | 71.22% |
Conclusions
I guess I need to summarize things I learned with much time spent on this topic for purposes of future references:
Find a suitble dataset to focus on when testing with your ideas. I begined by using the UCI’s 30 classes data set. This dataset is small with high between-class similarity for some classes and high in-class variations. This brings additional challenges for some of the ideas. Actually, I have to test many previous ideas again after I decided to focus on the swedish leaf dataset, where the performance is more robust for evaluation purpose.
As for the architecutre design, it may be better to start with those state-of-art-models to see if certain part or the whole can be migrated with modifications for your own project. Though the process of “rediscovery” could be fun, it may exhaust a lot of time…
Should have a more systematic way for tuning many of the paramters and evaluating the model. It is better to write a script that logs changes so that you do not lose those good paramters tried.
The details of this post can be found in here